Sistemas de recomendación, restaurantes y reseñas: Más allá de la media
Abril de 2021
Los consumidores prestan cada vez más atención a las reseñas en lÃnea antes de tomar una decisión de compra o de consumo. El 91% de las personas leen reseñas de manera ocasional o regular, y el 84% confÃa en las reseñas online al mismo nivel que en recomendaciones personales (Gather-Up, 2018). Sin embargo el 50% de los consumidores no escribe reseñas ni califica a los restaurantes (Gather-Up, 2018), y este desbalance entre la producción y el consumo de reseñas dificulta la construcción de una imagen clara de la calidad y la experiencia de un restaurante, y la limita a los puntos de vista de los usuarios que sà reseñan.
Sistemas de recomendación
Los sistemas de recomendación manejan tres tipos de objetos: Ãtems, usuarios y transacciones. Los Ãtems son cualquier elemento por recomendar, en este caso, los restaurantes. Luego está el usuario, a quien se ofrece las recomendaciones. Y tercero, las transacciones, que son la unión entre usuarios e Ãtems, que en este contexto son las visitas a restaurantes de un consumidor.
Generalmente, los sistemas de recomendación se clasifican en dos tipos: Content-Based Filtering (filtrado basado en contenidos).los cuales le ofrecen al usuario Ãtems similares a los que consumió en el pasado; y Collaborative-Filtering (filtrado Colaborativo), los cuales ofrecen al usuario Ãtems que personas con gustos similares al suyo evaluaron de manera positiva en el pasado.
A pesar de la amplia investigación en sistemas de recomendación, en la academia, el uso de técnicas de procesamiento del lenguaje natural (NLP) en idiomas distintos al inglés junto con sistemas de recomendación es bastante limitado. Debido a lo anterior, decidà desarrollar y evaluar un sistema de recomendación basado en procesamiento del lenguaje natural enfocado en el contexto de restaurantes.
Acoté este proyecto al contexto a la industria de restaurantes de Bogotá (Colombia). En Colombia, la aparición del COVID-19 y las consecuentes medidas preventivas de cuarentena obligatoria tuvieron un fuerte impacto en la industria de los restaurantes y bares. De febrero a marzo de 2020 este sector presentó una variación de -33% en los ingresos percibidos (DANE, 2020). Además, a pesar de que la industria de restaurantes aporta el 4% al PIB de Colombia y cerca del 6% de los empleos del paÃs (León, 2016), solo el 40% de los restaurantes llega a los cinco años (Nuñez, 2018).
Fuentes y obtención de los datos
En todo ejercicio de Data Science, uno de los factores más importantes (sino el más importante) es la calidad de los datos. AsÃ, la fiabilidad de las reseñas fue un factor clave, pues si las reseñas no reflejan la realidad del restaurante (siendo posible un sesgo hacia opiniones positivas o negativas) las recomendaciones no serÃan correctas.
El 94% de los consumidores evalúa las reseñas de Tripadvisor como más fiables, rigurosas, útiles y descriptivas. Y el 90% indica que las reseñas de Tripadvisor coinciden con las experiencias reales en los restaurantes, comparado con un 31% de Google y 18% de Facebook (Influences on Diner Decision-Making Survey, 2018). Es por esto que decidà obtener las reseñas y la información propia de los restaurantes de los restaurantes de TripAdvisor usando Web Scrapping [1] .

Análogamente, sin datos correctamente organizados, con duplicados, o con errores, se llegarÃa a conclusiones erróneas. Por lo que se hizo un proceso de limpieza para pasar de los datos en bruto a un modelo de datos (Figura 1). Entre las modificaciones realizadas destacan: la eliminación de duplicados y valores nulos; la corrección y unificación de valores con distinta ortografÃa; y el uso del API de Google Maps para enriquecer la información geográfica de los restaurantes, y para completar información faltante en algunos de ellos.
Por su parte, las reseñas, al ser textos libres, se catalogan como información no estructurada. Para darles la estructura necesaria para que fuesen usadas para el modelado se automatizó un proceso de limpieza que cambió el texto a minúsculas, corrigió la ortografÃa, reemplazó caracteres repetidos innecesarios y eliminó stop-words [2] . Además, se usó el modelo CoreNLP (Manning et. al. 2014) para hacer lematización del texto [3] .Como resultado de este proceso se obtuvo un set de datos con 2.130 restaurantes, 92.024 reseñas y 42.449 usuarios.
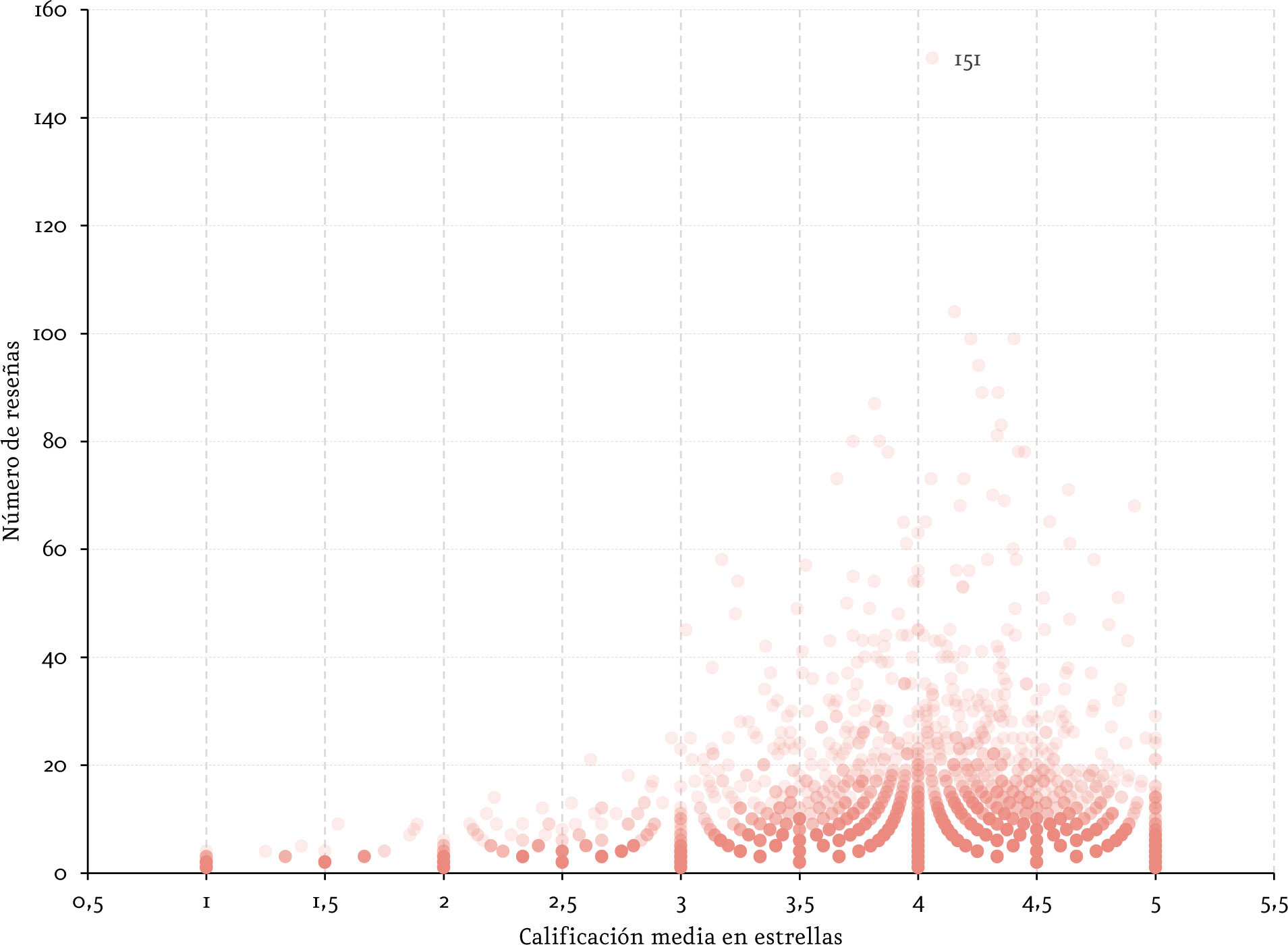
La mayorÃa de las reseñas asignadas por los usuarios son de 5 o 4 estrellas. Es decir, la mayorÃa tiene experiencias satisfactorias con los restaurantes que visita o tiende a escribir reseñas cuando tiene una experiencia positiva. De 2.130 restaurantes posibles, en promedio, un usuario solo habrá evaluado dos de ellos. Esto deja en evidencia una marcada situación de data-sparsity. [4] De hecho, de la totalidad de posibles parejas (usuario-restaurante) tan solo el 0.1% están presentes.
Al analizar las palabras más usadas en cada calificación de reseñas de manera comparativa se ve que conforme aumenta el número de estrellas, aumentan los calificativos positivos, especialmente los relacionados con ´recomendado´ y ´delicioso´. Mientras que las reseñas 1 o 2 estrellas hacen más énfasis en el servicio y la atención.


Division de datos y modelado
El conjunto de variables (features) de los restaurantes se construyó con base en el texto pre procesado: luego de agrupar por los niveles de puntuación (de 1 a 5 estrellas) se aplicó el método TF-IDF normalizado, se seleccionaron para cada nivel las 100 palabras más importantes y se hizo un perfil por restaurante usando una representación de bag-of-words sobre las 500 palabras más importantes. Para hacer una estimación correcta del desempeño de cada modelo, se dividió el dataset en dos particiones: Entrenamiento (80%) y Prueba(20%). [5]
De los modelos probados destacan los siguientes:
Singular Value Descomposition
Es un método basado en álgebra lineal que permite la reducción de dimensionalidad. Se basa en la factorización de matrices, y no hace uso de features textuales. Se enmarca entre las técnicas de filtrado colaborativo, y utiliza una matriz en la que cada fila representa un usuario, cada columna un Ãtem y los elementos de esta matriz son las calificaciones.
Modelo Light FM
Es el modelo implementado en la librerÃa del mismo nombre, propuesto por Kula (2015). El modelo aprende embeddings [6] para consumidores y restaurantes de una manera que codifica las preferencias del consumidor sobre los restaurantes. Este modelo tiene dos caracterÃsticas principales: 1) Aprende a partir representaciones de Ãtems y usuarios. Y 2) Permite computar recomendaciones a usuarios e Ãtems nuevos. [7]
Modelo de Reseña mixta
Desarrollé un modelo similar al planteado por Pero & Horváth (2013), el cual contempla tanto el sentimiento de la reseña como la calificación de la misma. Este modelo tiene dos partes: por un lado, primero se estiman los sentimientos de la reseña (positivo o negativo) para crear calificaciones virtuales, y a estas se les aplica el un procedimiento de factorización de matrices (SVD en este caso) [8].
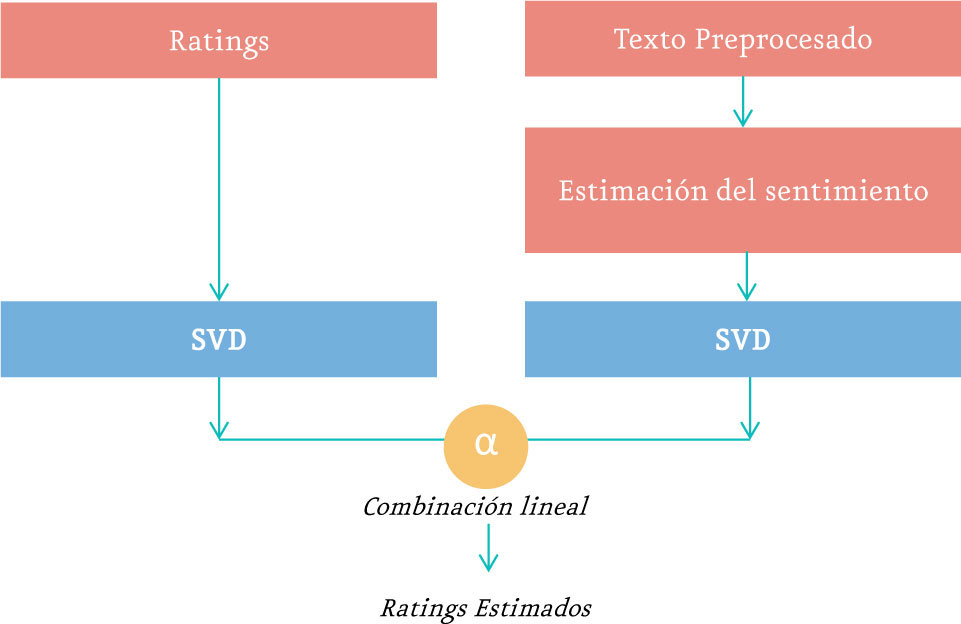
Por otro lado, a las calificaciones dadas por los usuarios se le aplica SVD. Y finalmente, se hace una combinación lineal de las calificaciones predichas por cada una de las matrices para dar una calificación final sobre la cual se ordenan los resultados y se dan las recomendaciones.
Rfinal = Rvirtual * α + Rreal * (1 - α)
Métricas
Para medir los modelos y compararlos entre sÃ, se usaron principalmente tres métricas:RMSE, Average Precision at K y Average Accuracy at K.
La evaluación con RMSE funciona de la siguiente manera: el modelo genera predicciones de las valoraciones para un consumidor, y luego se comparan las predicciones contra los valores reales por medio de la fórmula de RMSE. La ventaja de este enfoque es que no cae en el error de penalizar al sistema en caso de que haya recomendaciones de items que el usuario no ha evaluado.
La Precision at K (P@K) es la proporción del top K recomendaciones que son relevantes para
un usuario. Por ejemplo, si K =10, serÃa el porcentaje de los restaurantes que son relevantes que llegan al top 10 (para un usuario dado). Luego, si se hace por usuario una media de la P@K para K valores (K=100), se consigue la Average Precision at K (APK) . Y si luego se hace una media de estas APK entre los usuarios, se obtiene la Mean Average Precision at K.
De manera similar, la Recall at K (R@K) es la proporción de los Ãtems relevantes que llegan al top K. La Average Recall at K se calcula por usuario una media de la R@K para K valores (K=100), y la Mean Average Recall at K es el promedio estos valores.
| Modelo | Baseline [9] | SVD | LightFM | Reseña mixta (RM) |
| RMSE - Train CV | 1.251 | 1.03 | - | 1.002 |
| RMSE - Test | 1.258 | 1.04 | - | 1.02 |
| Mean Average Precision at K - Test | 0.601 | 0.640 | 0.695 | 0.682 |
| Mean Average Recall at K - Test | 0.125 | 0.165 | 0.232 | 0.184 |
En términos del RMSE, los modelos SVD y RM logran significativamente mejores resultados que el modelo baseline. El modelo RM al integrar las calificaciones virtuales de los restaurantes y computarlas en conjunto con las del modelo SVD logra un error menor diferenciado por su segundo decimal, lo que para efectos prácticos podrÃa considerarse un resultado igual al del SVD.
La Mean Average Precision at K indica que en promedio el 60% de los Ãtems recomendados son relevantes para el usuario en el modelo baseline. Esto tiene sentido al considerar que la mayorÃa de las reseñas tienen calificaciones de 4 o 5 estrellas. Los modelos LightFM y Reseña Mixta propuestos alcanzan en esta métrica valores de 0.70 y 0.68 respectivamente, superando a SVD.
A pesar de usar técnicas de NLP no se consiguieron mejoras significativas frente al modelo SVD. Esto puede deberse a varias razones, una de ellas es la data-sparsity del dataset. El dataset solo tiene un 0.1% de las posibles parejas usuario-reseña, lo cual dificulta a cualquier algoritmo el cálculo de recomendaciones, y perjudica las métricas en casos en los que los usuarios tienen un bajo número de reseñas.
Los resultados demuestran que los modelos basados en texto ofrecen una mejora sobre aquellos que solamente tienen en cuenta las calificaciones otorgadas a los restaurantes por parte de los usuarios.Sin embargo, el grado de data-sparsity de los datos es determinante en la consecución de buenas predicciones, pues incluso tras incluir información textual, las mejoras a la hora de hacer recomendaciones son marginales si no existen suficientes reseñas.
Referencias
- Gather-Up. (2018). Online Reviews Study: Restaurants & Reviews. Gather Up. https://gatherup.com/blog/online-reviews-study-restaurants-reviews/
- DANE. (04/2020). Encuesta mensual de servicios (EMS) . Departamento Administrativo Nacional de EstadÃstica. https://www.dane.gov.co/files/investigaciones/boletines/ems/bol_ems_abril_20.pdf
- León, D. (2016, July 10). Restaurantes del paÃs aportan 4% al PIB. Vanguardia. https://www.vanguardia.com/economia/nacional/restaurantes-del-pais-aportan-4-al-pib-CFVL375667
- Nuñez, G. E. (2018, December 29). Muchos restaurantes no llegan a los cinco años: Acodres. https://diariolaeconomia.com/fabricas-e-inversiones/item/4130-muchos-restaurantes-no-llegan-a-los-cinco-anos-acodres.html
- Pero, Š., & Horváth, T. (2013). Opinion-Driven Matrix Factorization for Rating Prediction. In User Modeling, Adaptation, and Personalization (pp. 1-13). https://doi.org/10.1007/978-3-642-38844-6_1
- Manning, Christopher D., Mihai Surdeanu, John Bauer, Jenny Finkel, Steven J. Bethard, and David McClosky. 2014. The Stanford CoreNLP Natural Language Processing Toolkit In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pp. 55-60.
- Hug, N., (2020). Surprise: A Python library for recommender systems. Journal of Open Source Software, 5(52), 2174, https://doi.org/10.21105/joss.02174
- Kula, M. (2015). Metadata Embeddings for User and Item Cold-start Recommendations. arXiv Preprint.
- Chen, L., Chen, G., & Wang, F. (2015). Recommender systems based on user reviews: the state of the art. In User Modeling and User-Adapted Interaction (Vol. 25, Issue 2, pp. 99-154). https://doi.org/10.1007/s11257-015-9155-5
[1] Método que simula el comportamiento humano en una página, y que de manera masiva obtiene la información de una página web. La obtención de datos de Tripadvisor se limitó a las 300 primeras reseñas por restaurante para no violar ninguna ley de propiedad de los datos, y no se obtuvo informa.
[2] Palabras sin significado como artÃculos, pronombres, preposiciones, etc. Y que no agregan valor al análisis. Para esto se usó la librerÃa NLTK.
[3] La lematización consiste en reemplazar las formas flexionadas de una palabra por su lema correspondiente (como se encontrarÃa en un diccionario) basado en su significado. Por ejemplo, de «ExcelentÃsimo» por «excelente», o «Comimos» por «comer».
[4] Si se contempla una matriz de dos dimensiones en la que en un lado están los restaurantes y en el otro los usuarios, se tiene que se cubren muy pocas de todas las posibles combinaciones.
[5] Debido al data sparsity se decidió tener en Train la mayor cantidad de datos, sin que Test dejase de ser representativo. Sobre el de Train se hizo cross-validation de 5 folds para los algoritmos que requirieron encontrar hiper parámetros. Los hiper parámetros se optimizaron usando grid-search. Los modelos finales fueron entrenados en la totalidad de datos de Train.
[6] Representaciones latentes en un espacio de alta dimensión.
[7] Los usuarios y los Ãtems se pueden describir dadas sus features, y estas son conocidas con antelación y representan meta-datos de usuarios y de Ãtems. Para este caso se tienen en cuenta sólo features de los Ãtems, dado que no se tiene información de los usuarios. Estas features fueron los vectores resultantes del proceso de Bag-of-words.
[8] Se usó la librerÃa Senti-py que tiene un modelo para la detección de sentimiento en español. Para el método SVD se usó la librerÃa Surprise.
[9] El modelo baseline fue un modelo regresivo que contempla una media general, y las desviaciones del usuario y del restaurante.

