Utilizando «Data Science» para encontrar nuestro restaurante ideal
Febrero de 2019
La empresa estadounidense Yelp, fundada por Jeremy Stoppelman y Russel Simmons, es una plataforma que actúa como red social y permite a los usuarios subir y compartir fotos y opiniones de los restaurantes y establecimientos que visitan. Actualmente Yelp aloja millones de fotos de restaurantes cargadas por sus usuarios de todo el mundo.
Con el fin de poder procesar dichas fotos de manera automática, Yelp presentó en la plataforma Kaggle un desafÃo titulado «Clasificación de fotos de restaurantes de Yelp»[1]. Dicho desafÃo consiste en construir un modelo que asocie automáticamente restaurantes con múltiples etiquetas, usando un conjunto de datos de fotos subidas por los usuarios a su plataforma.
Análisis de los datos
Para el desarrollo del trabajo se utilizó el set de datos de dicha competencia, dividido en particiones de train y test. La partición de train, con 230.000 imágenes pertenecientes a 2.000 restaurantes, fue utilizada para entrenar los distintos modelos que iré utilizando. La partición de test, con 240.000 imágenes pertenecientes a 10.000 restaurantes, fue utilizada para evaluar el desempeño de los modelos utilizados.
Las imágenes del set de datos tienen resolución media de 375*500 pÃxeles. Para unificar tamaños, fueron ajustadas a 96*96 pÃxeles. Además, para lograr una correcta representación digital de las caracterÃsticas de cada imagen, se ajustaron sus niveles de iluminación, contraste y desenfoque.
El objetivo del trabajo, al igual que el del desafÃo, fue etiquetar a cada restaurante con una o más de las siguientes etiquetas:
- Good for lunch: Bueno para almorzar
- Good for dinner: Bueno para cenar
- Takes reservations: Toma reservas
- Outdoor seating: Mesas exteriores
- Restaurant is expensive: Restaurante caro
- Has alcohol: Tiene alcohol
- Has table service: Tiene servicio de mesa
- Ambiance is classy: Ambiente elegante
- Good for kids: Bueno para niños
En la siguiente figura se pueden observar algunas de las imágenes del set de datos con sus respectivas etiquetas.

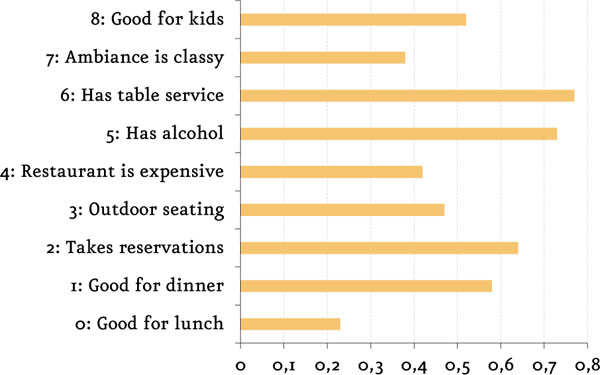
Dentro de las 9 posibles etiquetas para cada restaurante, y tal como se puede observar en la siguiente figura, se detecta que no todas están asignadas uniformemente en la misma cantidad de imágenes. Las etiquetas que más se repiten, con ocurrencia en más del 75% de las imágenes, son «Has table service» y «Has alcohol». La que menos se repite, con ocurrencia del 24% es «Good for lunch». Sin embargo, mantendré las clases desequilibradas ya que las clases mayoritarias son las que más importan a las personas a la hora de ir a un restaurante.
(%)
Modelización
Una vez entendido el problema y los datos que tenemos para resolverlo, lo primero que hice fue comparar distintas técnicas y modelos que me permitieran asignar etiquetas a cada imagen.
Todos los modelos que probé fueron evaluados mediante la métrica F1 o F1 score [2], la misma que fue utilizada en el desafÃo publicado en Kaggle para seleccionar al equipo ganador.
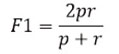
La métrica F1 brinda un equilibrio en el rendimiento tanto para la «precision» (p) como para el «recall» (r), e intenta optimizarlos conjuntamente.
Como a priori es difÃcil saber qué algoritmo será el que mejor se acople al problema, utilicé una técnica llamada spot checking [3] mediante la cual evalué distintos algoritmos sin ajustar sus parámetros, para dar rápidamente con el mejor de ellos.
Los algoritmos que probé mediante esta técnica fueron: Decision Trees, Gradient Boosting, k-Neighbors, Logistic Regression, Multinomial Naive Bayes, Random Forest y Support Vector Machines (SVM). En la siguiente figura se observa para cada algoritmo un boxplot con los 5 valores de F1 que fueron obtenidos luego de aplicar validación cruzada.
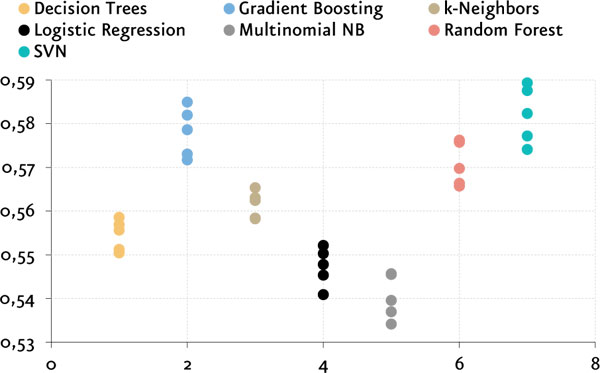
Los mejores resultados son obtenidos por los algoritmos SVM con F1 entre 0.57 y 0.59 y, apenas por debajo, Gradient Boosting con F1 entre 0.57 y 0.585. Sin embargo, ningún algoritmo logró superar la barrera de valores F1 superiores a 0.60, por lo que abordaré el problema desde la perspectiva del aprendizaje profundo o deep learning en busca de mejores resultados.
Un modelo de deep learning es diseñado para analizar continuamente los datos con una estructura lógica estratificada de algoritmos similar a la que utiliza un ser humano para sacar conclusiones, llamada red neuronal. El diseño de una red neuronal artificial está inspirado en la red neuronal biológica del cerebro humano, lo que hace que en problemas de alta complejidad la inteligencia de la máquina sea mucho más capaz que la de los modelos de aprendizaje automático estándar.
Para mi problema de clasificación de restaurantes, principalmente por ser imágenes mi objeto de estudio, utilicé redes neuronales con capas convolucionales que permiten extraer mayor cantidad de caracterÃsticas (features) de cada imagen, para luego clasificar dichas caracterÃsticas en las capas densas superiores de cada red.
Las arquitecturas de red que utilicé fueron las siguientes:
- Red convolucional base: basada en LeNet-5, introducida por Yann LeCun [4], que presenta dos grupos de capas convolucionales, seguidas de capas de pooling, una capa densa y, finalmente, un clasificador.
- Redes pre-entrenadas y transferencia de aprendizaje: arquitecturas de red más complejas con el fin de mejorar el rendimiento y precisión de la red. Hice pruebas sobre arquitecturas VGGNet[5] e InceptionV3[6]. Utilicé dichas redes pre-entrenadas sobre los sets de datos ImageNet[7] y Places365[8]. Por último, realicé un entrenamiento selectivo de sólo algunos bloques de sus capas superiores, para agilizar los tiempos de entrenamiento.
- Redes Ensemble: hice pruebas de agrupación sobre las arquitecturas anteriores en busca de una red más robusta. Utilicé dos formas para ensamblar las redes:
- Maximum: evaluando predicciones de cada modelo y tomando las predicciones máximas en cada caso.
Average: evaluando las predicciones de cada modelo y tomando el promedio de estas en cada caso.
Cada arquitectura fue entrenada y evaluada de forma remota en una instancia de Amazon Web Services Elastic Compute Cloud (AWS EC2) [9], haciendo uso de una GPU Tesla K80.
En la siguiente figura se pueden ver los rendimientos de cada arquitectura de red evaluada, al igual que con los algoritmos anteriores antes, con el score F1.
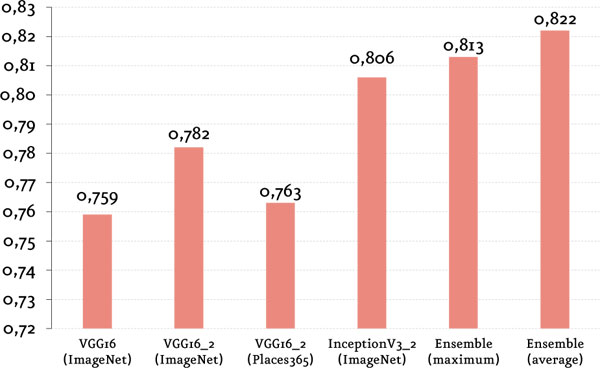
El modelo Ensemble (average) fue el modelo que mejor respuesta consiguió frente al problema de etiquetado múltiple, ya que es el que mejor valor F1 obtuvo y el que posiblemente mejor se comporte cuando se lo ponga a prueba en producción para etiquetar nuevas imágenes. Todas las arquitecturas de red superaron ampliamente a los algoritmos probados anteriormente en el spot checking.
En la siguiente figura se observan las curvas de evolución de la pérdida (loss) y valor de F1 a lo largo del entrenamiento del modelo Ensemble (average) . El mismo finalizó su entrenamiento en la época 30, y obtuvo su mayor rendimiento en la época 23.
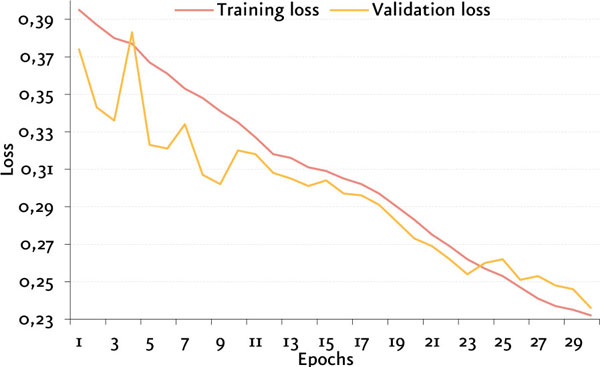
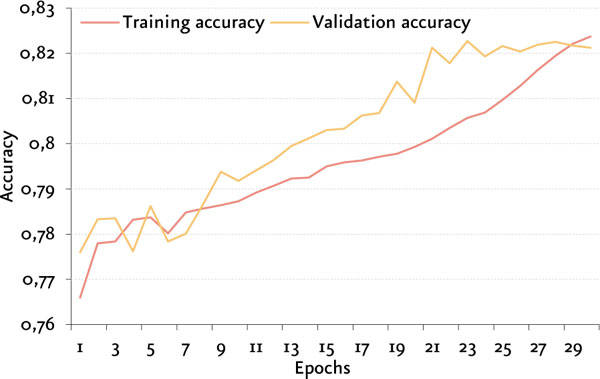
Resultados
Los resultados obtenidos sirvieron para cumplir con el principal objetivo del trabajo. Es decir, se logró crear un modelo que asigne múltiples etiquetas a imágenes de restaurantes, lo que conllevó experimentar gran variedad de algoritmos y redes neuronales, y permitió arribar a una solución con resultados más que adecuados para el problema, logrando sólo un 3% menos de rendimiento que la solución ganadora, lo que significa que este trabajo se hubiera posicionado en un hipotético 35o lugar de la competencia de Kaggle en la cual se presentaron más 350 equipos.
Se presentó como modelo final el Ensemble (average) de redes neuronales. Dicho ensemble logró el mejor valor de F1: 0.822 con las imágenes de train y 0.803 con las imágenes de test, superando ampliamente a los algoritmos del spot checking y a las demás arquitecturas de red. Sin embargo, no hay modelos perfectos y, al ser puesto en producción, es probable que en ciertos casos falle.
El desarrollo completo del trabajo y los distintos bloques de código utilizados en el mismo pueden ser accedidos en la memoria del TFM [10], donde también hay otras pruebas realizadas sobre el set de datos, tales como reducción de dimensionalidad y pruebas de etiquetado mediante clustering y aprendizaje no supervisado.
Nota: este artÃculo es un extracto del trabajo de fin de curso del Master en Data Science y Big Data 2017-2018, Afi Escuela de Finanzas.
[1] «Yelp Restaurant Photo Classification», publicado en Kaggle. Consultar aquÃ.
[2] «Métrica de evaluación F1 score». Consultar aquÃ.
[3] «How to Develop a Reusable Framework to Spot-Check Algorithms». Consultar aquÃ.
[4] «LeNet-5, convolutional networks». Consultar aquÃ.
[5] «Very Deep Convolutional Networks for Large-scale Image Recognition» por Karen Simonyan y Andrew Zisserman. Consultar aquÃ.
[6] «Rethinking the Inception Architecture for Computer Vision» por Christian Szegedy, Vincent Vanhoucke y Sergey Ioffe. Consultar aquÃ.
[7] «ImageNet dataset». Consultar aquÃ.
[8] «Places dataset». Consultar aquÃ.
[9] «Amazon Elastic Compute Cloud (Amazon EC2)». Consultar aquÃ.
[10] Memoria TFM «Análisis clasificatorio de imágenes de restaurantes» por MatÃas Caputti, Junio 2018. Consultar aquÃ.
 MatÃas Nicolás Caputti es Graduado del Máster en Data Science y Big Data de Afi Escuela de Finanzas.
MatÃas Nicolás Caputti es Graduado del Máster en Data Science y Big Data de Afi Escuela de Finanzas.
